SparseArray是谷歌为安卓专门推出的一种数据结构,它没有自动装箱机制,在特定情况下比HashMap的效率要高。当然这些只是官方的说法,这篇文章主要探讨一下这种数据结构的实现,至于效率问题不做研究。
简要介绍
SparseArray底层采用两个相同容量的数组实现,key和value,其中key必须是int型,value则是指定的泛型,这样也就解释了为什么没有自动装箱,因为key数组就是int数组。
构造方法有两种,指定初始容量和不指定初始容量,后者默认初始容量是10.
它提供了与map类似的一些接口:
1 | //获取key所对应的value值 |
结构分析
首先介绍一下二分查找法,这种查找必须针对于已经按递增/递减顺序排序好的数组,这是一种快速的查找方式,时间复杂度是log2n。
给一张简单的示意图:
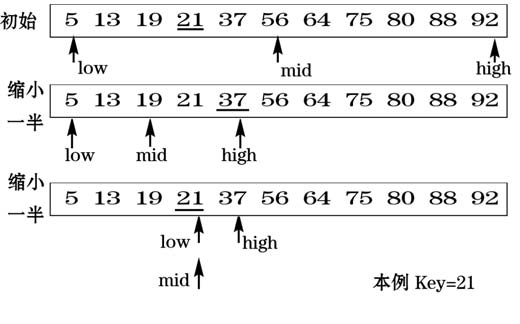
在SparseArray中使用的二分查找代码如下:
1 | static int binarySearch(int[] arrray,int size,int value){ |
采用标记法的好处就是假如下一次操作不需要触发重排序,则会省略一个遍历循环,比如下面要讲的插入操作。
插入
插入过程也是一个巧妙的过程,有效的利用了在二分查找中返回的最接近查找的值的索引位置的反码,并利用它来在这个位置插入心得元素。
简单的看一下插入的源码:
1 |
|
简单说一下方法中的第一行代码是查找key的索引,2、3行便是假如找到了,就直接替换这个key上的vlaue值,假如未找到,则执行插入操作。这里插入也两种方式:
- 要做插入位置已经被标记为删除了,则直接替换原有的值
- 要插入位置未标记删除删除,则直接插入,容量不够时自动扩容
讲到这里基本就明白了SparseArray的结构形式,它和HashMap是完全不同的两种结构。这里稍微将一下hashmap的原理,1.7版本的HaspMap底层采用数组和链表形式,每个Entry构成一个链表,这些链表再组成数组,这样做的好处是可以解决hash碰撞,并能根据hash码快速查找桶的位置。但是HashMap必须使用泛型来作为key,所以会遇到自动装箱的问题,在不可避免的情况下,使用final类可以稍微提高效率。这也就是SparseArray宣传的要比HashMap快的原因,但是后者的应用范围更广一些。
除了SparseArray以外,安卓还提供了一些特定类型的数据结构,SparseBooleanArray,SaprseIntArray和SparseLongArray,这三个类用于存储boolean、int和long类型,理论上是比SparseArray要快一些,因为它的value省去了自动装箱,使用的基本类型数组。
最后分享一个我自己正在维护的基于编译期注解实现时间轴效果的控件:
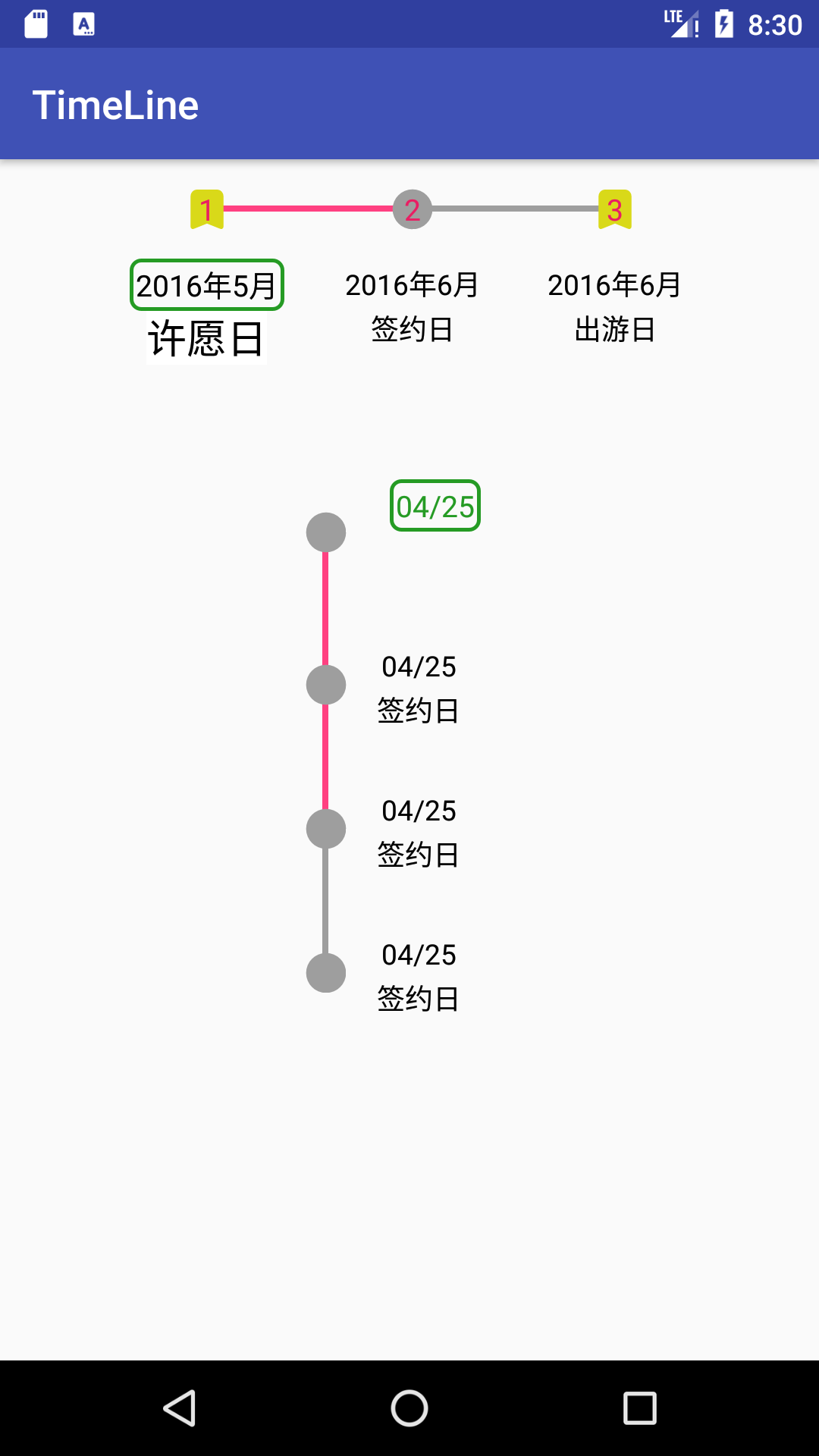
只需要添加一些注解就可以生成adapter,目前还在雏形,需要平衡易用性与复杂度的关系。